最近在抓取一些比较有价值的网站资源,用于训练AI写作系统,保证AI能在我采集的庞大数据库中学会利用一个命题就可以创作高质量原创文章。对!我说的是原创文章,不是伪原创。至于这个AI写作的系统将会在我成功后与大家展开更为细致的分享,今天我们的主题是,如何通过火车头采集器批量采集网站文章。
一、准备
软件:火车头采集器/高铁采集器
使用环境:PC端
二、采集
1.获取列表页数据
进入待采集网站,打开需要采集的栏目或者待采集的关键词搜索列表。

确定这个栏目的文章页数,翻到底部发现总页数为15,确定采集页数为15。
跳转到下一页,确定网页的起始网址格式,变量基本是.html前面的序号,所以我们先直接复制下来。
进入高铁采集器,点击+按钮跳出任务设置页面。

点击网页采集规则页面的起始网页右边的第一个按钮进入向导,填入复制下来的页面地址,并将页面的变量替换成右边的地址参数,直接删掉原页码然后点击按钮插入就可以。
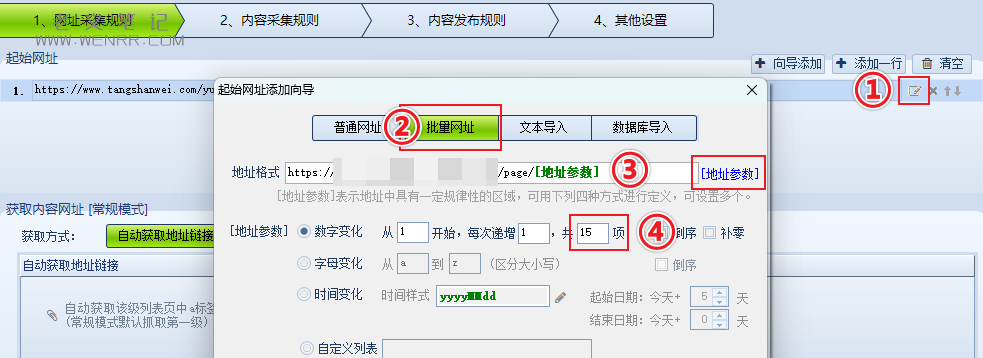
最终会自动生成一个采集列表文章的链接,但这只是采集页面数据,并没有将需要的内容精确地采集到。
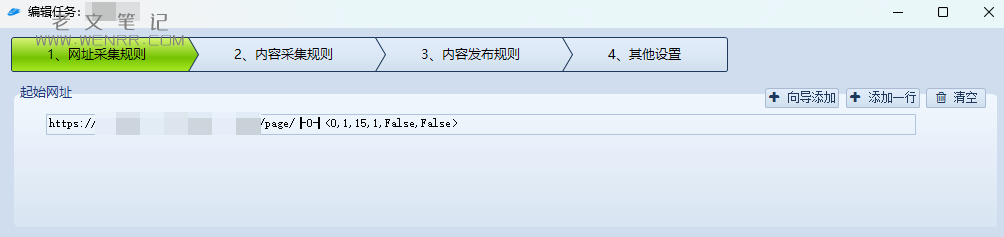
因为需要让机器知道我们要采集哪些数据,所以我们要在网页代码中找到开头和结尾的标志,以便机器采集。
右击网页空白处查看网页源代码
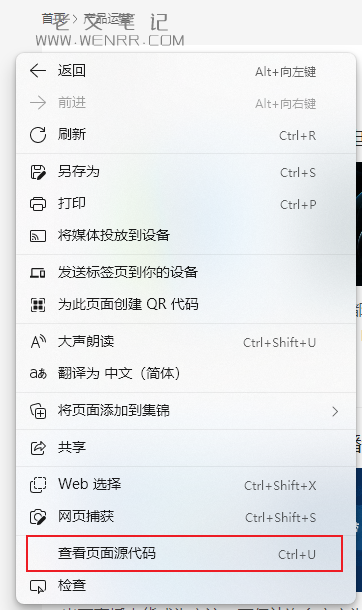
由于源码大多是一行显示,所以我们需要勾选源码顶部的“换行”复选框。
Ctrl+F 搜索源代码中包含列表页的第一条数据的标题,并寻找与该标题临近的一个唯一标签。
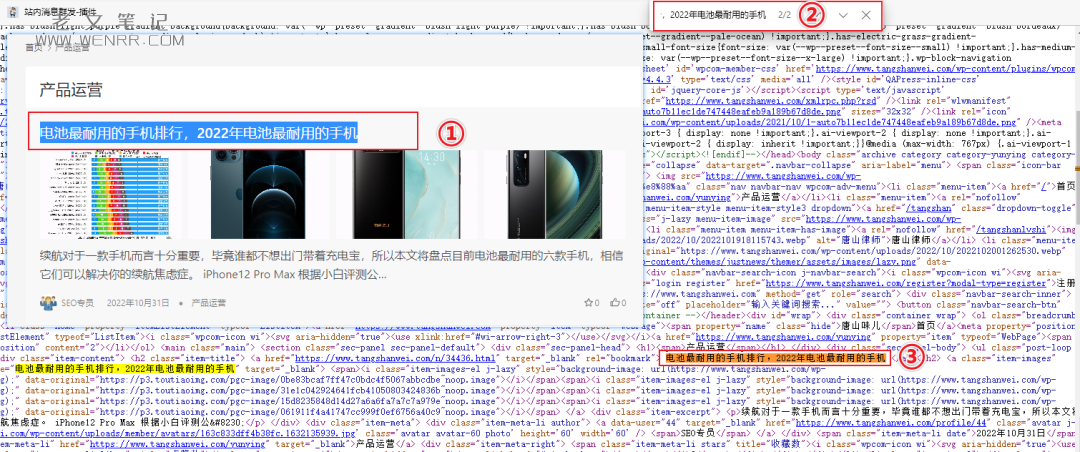
<h1><span>产品运营</span></h1> </div> <div class="sec-panel-body">在这段代码中,我选择了 “<divclass=”sec-panel-body”>” 作为识别开头的代码。
同样的方式,我搜寻列表页的最后一条数据的标题,找到了识别结尾的代码。
是否是唯一且能识别到的代码,我们也可以通过 Ctrl+F 去查找,只要搜索数据是唯一的就是了。
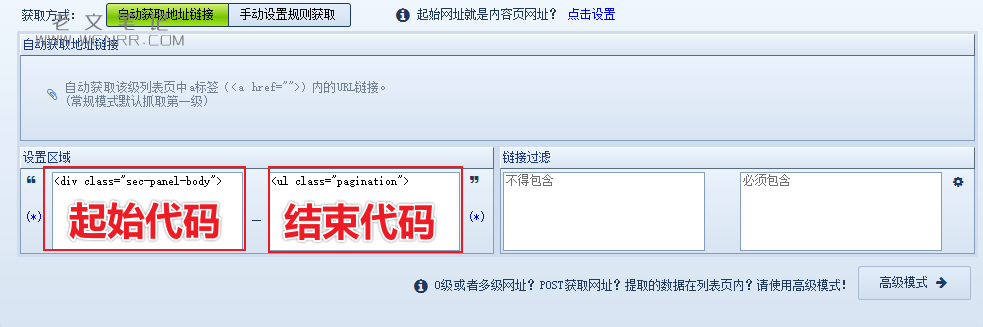
填入写好的起始和结束代码后,点击右下角的网页测试按钮测试采集数据是否正常。
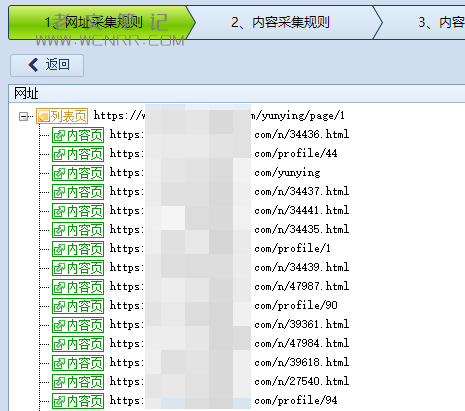
让机器采集一部分列表页数据就可以停止了,然后看到采集的数据是比较多的,有些数据不是我们需要的数据页,所以我们需要将其排除。
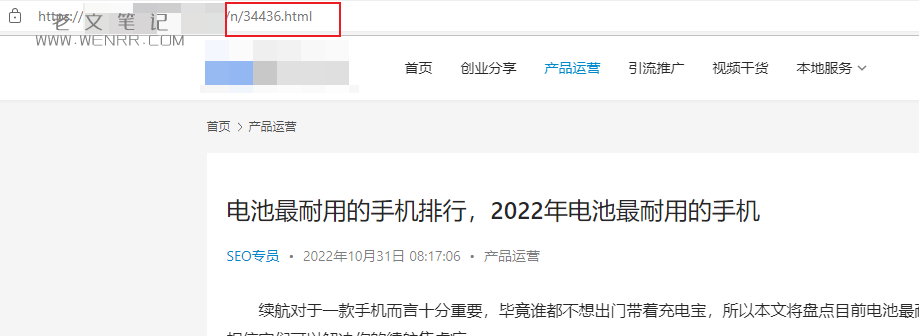
查阅到内容页的地址为/n/(*).html,所以我们可以用网页格式去锁定采集地址。
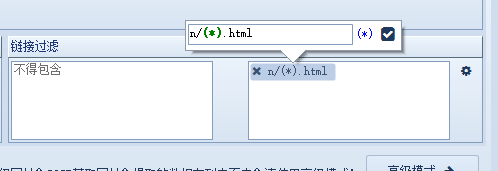
在链接过滤处选择链接包含并填入刚才的格式
接下来发现内容页地址采集正常。
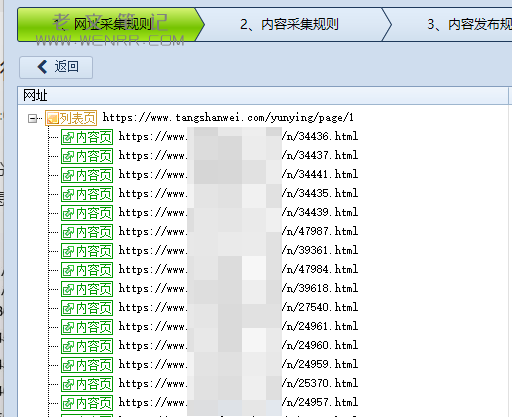
2.获取内容页数据
接下来我们就需要写内容页的采集规则,这里比较复杂,需要认真看。在最近的测试中,发现对于新手来说也并不是难事,因为逻辑一样的,多去调试就行了。
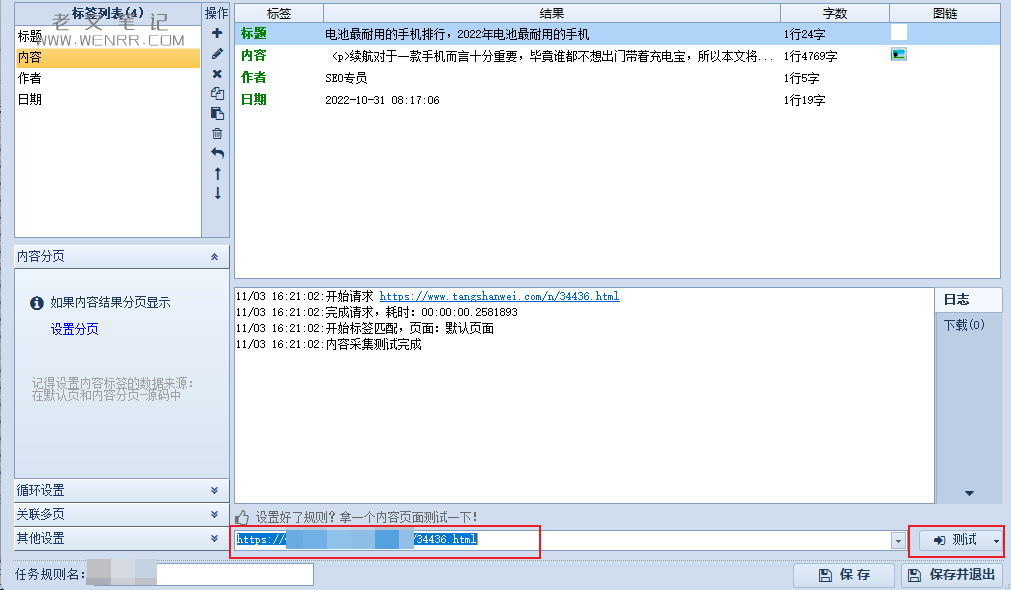
进入内容采集规则页面,内置有标题和内容,这里我多加两条数据“作者”和“日期”,以便大家更深理解。
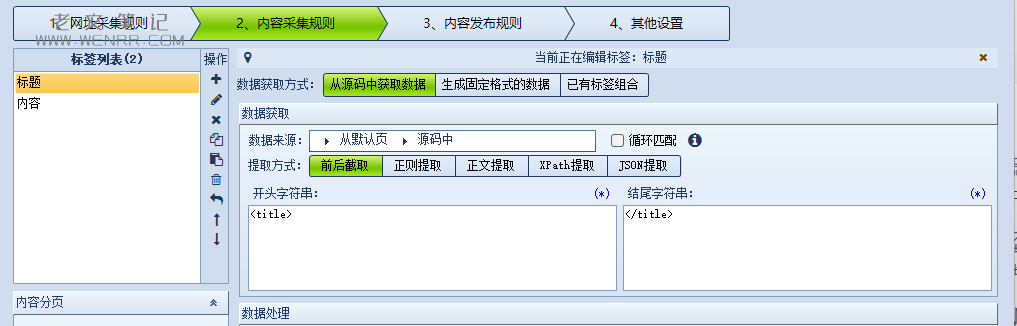
我们在采集过程中可能需要更多的数据,基本上都可以按照我说的操作采集出来。
同样,在文章页面右击调出源代码,我按标题、作者、时间、内容的顺序教大家写采集规则。
首先,我们查找到文章标题的位置,确定位置在<h1>标签内,起始大部分的页面都是<h>标签,只是里面的样式不同而已。

<h1 class="entry-title">标题</h1>接着直接看后面的代码,通过一些标志,看到作者和时间,这时候就确定了时间和地址。

<a class="nickname url fn j-user-card">作者</a> </span> <span class="dot">•</span> <time class="entry-date published" datetime="2022-10-31T08:17:06+08:00" pubdate> 2022年10月31日 08:17:06 </time>然后再看接下来的内容,去找找内容的代码。
通过文章内容找到旁边的div标签是唯一识别的标签(经验之谈,一般在class中包含content),咱们就可以确定内容的开始标签。

<div class="entry-content text-indent">同样的方法,找到结尾词旁边的标签为:
<div class="entry-readmore">这就确定了标题、作者、时间、内容了,接下来需要去软件内写清楚规则。
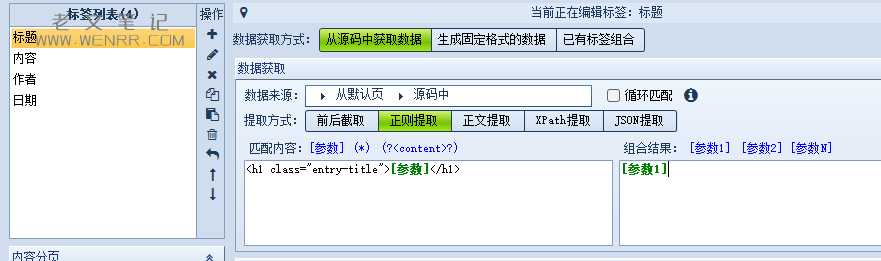
①标题
我们提取标题优先选择正则提取,并将复制的所有变量在匹配内容中用[参数]代替,在组合结果中直接点击[参数1]。
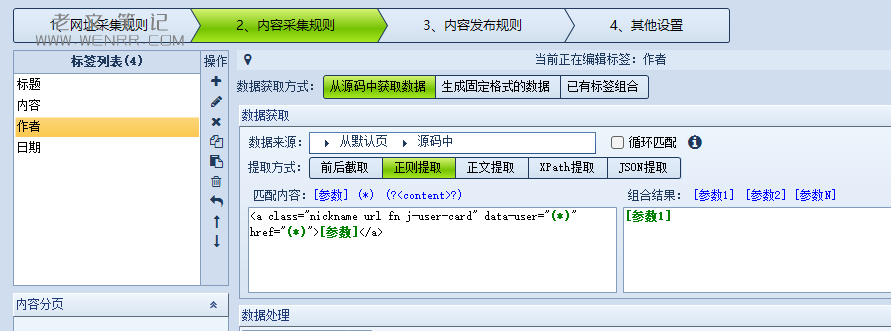
②作者
同样我也选择用正则提取,由于某些数据是变量且不需要,我们直接用(*)代替即可,需要的内容用[参数]替代,并在组合结果中选择[参数1]。
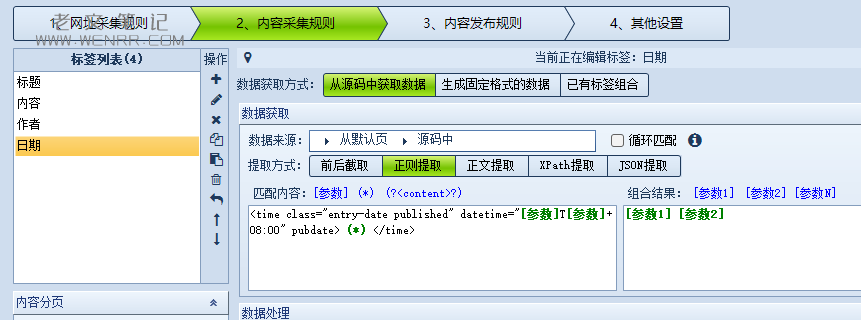
③日期
因为我想给大家讲一下为什么有[参数1]、[参数2]、[参数N],所以我使用多个参数进行举例。
在这里,我把标签中的参数作为我的结果,将标签中的内容直接丢掉了,但是获取的结果是一样的。
所以在写规则的时候也不一定要中规中矩按别人教你的来,只要保证数据准确就行。
④内容 这里不需要多说,因为前面我们分析过,前后截取的代码已经知道,直接填进去。
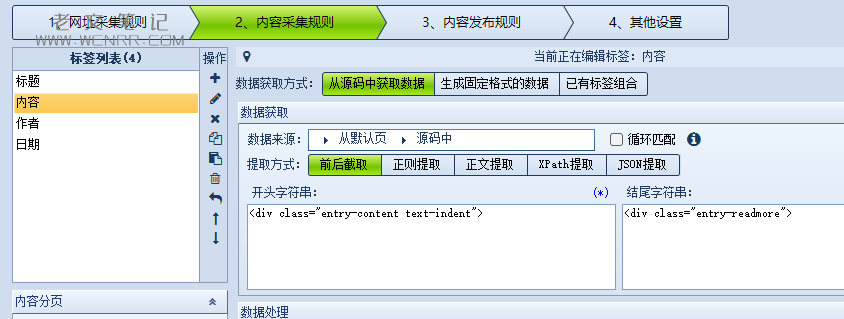
但是要考虑到不同页面中的开头和结尾可能是变量,所以我们要多打开一些文章去查看网页代码,毕竟某些页面开头有引言,有的结尾有版权声明。
三、测试
现在规则写好了,我们需要找个页面测试下,我们发现数据采集是正确的,现在基本的采集就完成了。
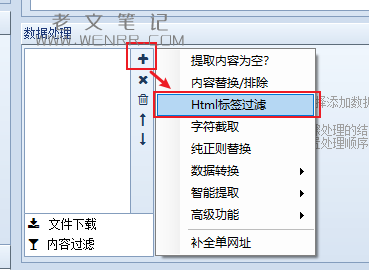
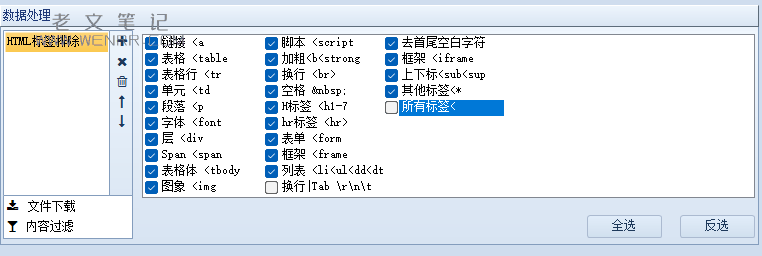
对于我来说,AI写作训练不需要标签,所以我需要在采集的时候直接过滤掉,所以我在内容标签下的数据处理中,选择html标签过滤,直接全选了所有标签。为了阅读方便,我取消了换行和所有标签,当然我们也可以通过对数据的处理输出我们需要的内容。
四、输出
我们不设置内容发布规则的话,会导致文章采集了无法输出。
由于我只需要将数据输出为文档供AI学习,包括web在线发布和导入数据库都包含比较复杂的对应关系,所以输出这里我只讲保存本地文件这一项。
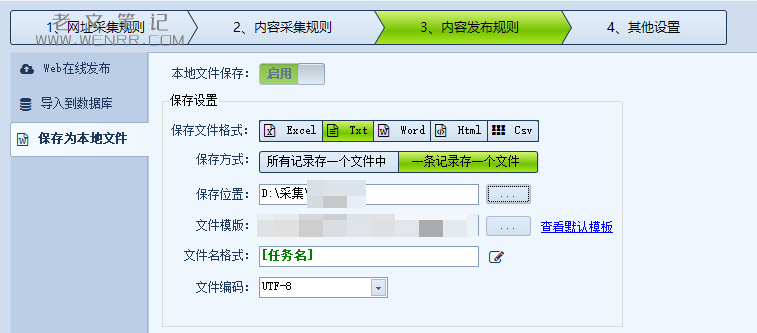
我们将本地文件保存打开,以txt文件格式输出为例,我们选择txt,并设置保存位置为自定义位置,文件模板我使用的是:

把它保存为txt文件,并将文件模板选择为这个文件,软件就会按照这个格式去输出文章了。
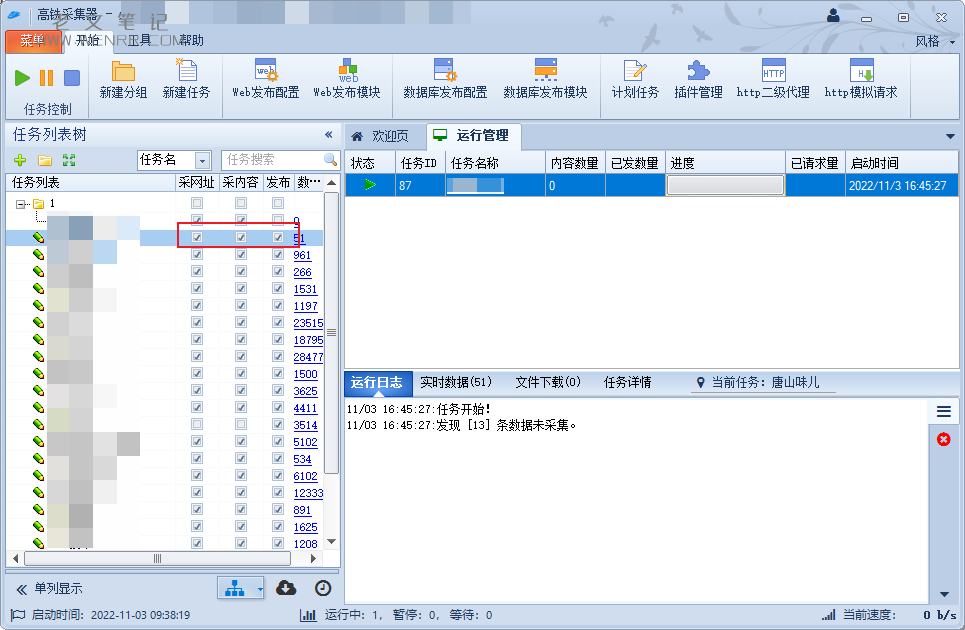
所有设置都配置好了之后就直接保存并退出,然后进入主页面,勾选任务右边的“采网址”、“采内容”、“发布”复选框,右击任务并选择开始即可,如果看到运行日志中运行正常就可以让它静默采集了,如果有提示错误,分析错误产生原因,然后对症下药就行了。
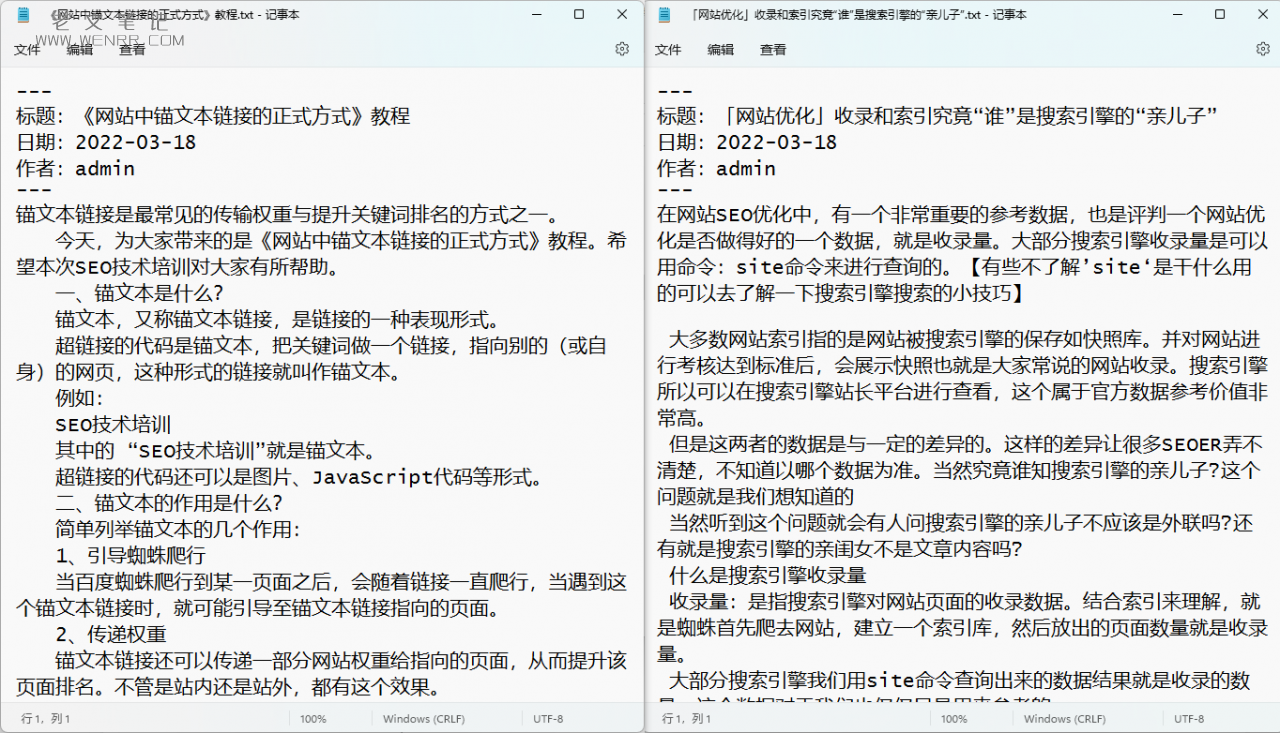
以下是输出的案例:
五、注意事项
我们在采集中一定不会像我说的这么简单,所以我把我遇到的坑提前告知大家,以免大家走弯路。
1.数据为空
采集的数据为空白有一部分原因是原文就是空白的,比如网页上面的问答,如果没有回答,他的内容就是空的。还有就是采集规则不适用于所有页面,重新制定新的规则,保证所有数据能够输出为止。
有时候我们采集的数据是全空,这大概率是因为网速问题或者是网站问题,重新采集即可,因为没有采集到的数据会标注未采和未发。
2.输出数据相同
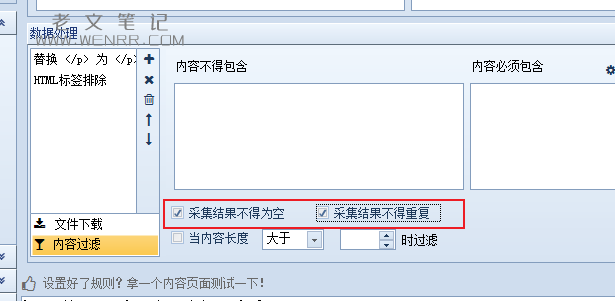
由于某篇文章在不同的标签或者板块下,软件不会直接帮你过滤,但是我们可以通过设置标签下的内容过滤,勾选“采集内容不得为空重复”的按钮。(勾选“采集内容不得为空”也可以解决问题1)
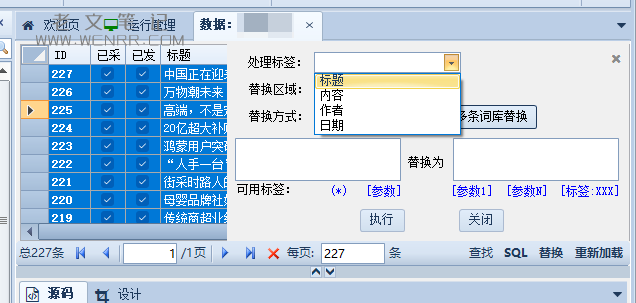
3.替换部分数据
这里我们在采集后会发现有很多版权词或者一些需要过滤的词,不必重新设置采集规则,而是在本地数据中,选择所有数据,并对特定标签中的特定内容直接进行替换或者过滤即可。
以上原创教程仅用于学术交流,请勿搬运或用于不法用途,大佬请直接关闭本文。
关于火车头/高铁采集器怎么使用,新手保姆级教程的相关内容;如有侵权,请联系老文删除。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫